
In diesem Tutorial werden die Grundlagen der Clusteranalyse beschrieben und die hierarchische Clusteranalyse mit der Ward-Methode in R umgesetzt.
Grundlagen
Die Clusteranalyse ist ein exploratives Verfahren um Ähnlichkeitsstrukturen in Daten zu erkennen. Bei den Untersuchungsobjekten einer Clusteranalyse kann es sich sowohl um Personen, Produkte oder um beliebige andere Einheiten wie Filme, Länder oder Unternehmen handeln. Durch die Anwendung der Clusteranalyse können diese Objekte anhand ihrer Eigenschaftsausprägungen zu Clustern zusammengefasst werden. Dabei soll jedes Cluster in sich möglichst gleichartig (homogen) sein und sich gleichzeitig von den anderen Clustern möglichst stark unterscheiden (heterogen). Beispielsweise erfasst der Streaminganbieter Netflix die Sehgewohnheiten seiner Abonnenten und hat auf dieser Grundlage über 2000 Mikro-Cluster, sogenannte “Taste Communities”, gebildet (New York Magazine, 2018). Den Mitgliedern der jeweiligen Clustern sollen anhand der jeweiligen Clusterzugehörigkeit möglichst passende Inhalte vorgeschlagen werden. Die Filme können dabei ebenfalls anhand unterschiedlicher Merkmale geclustert und im Anschluss mit aussagekräftigen Bezeichnungen versehen werden:
Wichtige Voraussetzungen, die bei der Durchführung der Analyse beachtet werden sollten (Universität Zürich, 2018):
- Die Analyse kann für unterschiedliche Datentypen (kategoriale und metrische Daten) genutzt werden.
- Fehlende Werte und Ausreißerwerte sollten vorab beseitigt werden.
- Weisen die verwendeten Variablen große Unterschiede bezüglich ihres Wertebereichs auf (bspw. wenn eine Variable in cm und die andere in km gemessen wurde), so sollten diese auf ein einheitliches Niveau transformiert werden. Üblicherweise wird dafür die z-Transformation genutzt.
Bei der Berechnung der Cluster wird nach bestimmten Regeln entschieden, wie die Objekte zu Clustern zusammengefasst werden. Das Ergebnis dieses Prozesses hängt nicht nur von der Wahl des Clustering-Algorithmus ab, sondern auch davon, wie die Distanz oder Ähnlichkeit zwischen den Objekten bestimmt wird.
Zu Beginn der Clusteranalyse wird daher in Abhängigkeit von den vorliegenden Datentypen ein sogenanntes Proximitätsmaß gewählt.
Proximitätsmaß
Mit Hilfe des Proximitätsmaßes wird die Distanz zwischen den Objekten berechnet. In Abhängigkeit von dem Skalenniveau der Variablen wird eine Distanzfunktion zur Bestimmung des Abstandes (Distanz) zweier Elemente oder eine Ähnlichkeitsfunktion zur Bestimmung der Ähnlichkeit verwendet:
Bei kategorialen (nominalen und ordinalen) Variablen werden Ähnlichkeitsmaße benutzt.
Bei metrischen Variablen werden Distanzmaße genutzt.
In diesem Tutorial behandeln wir die Distanzmaße “euklidische Distanz” (auch \(L_2\) genannt), “quadrierte euklidische Distanz” und die “L1-Distanz” (auch Manhattan-Metrik, Manhattan-Distanz, Mannheimer Metrik, Taxi- oder Cityblock-Metrik geannt).
Euklidische Distanz
Mit Hilfe der euklidischen Distanz kann der Abstand zwischen zwei Punkten als gerade Linie in einem Raum berechnet werden (“Luftliniendistanz”). Anders formuliert ist der euklidische Abstand zweier Punkte die mit einem Lineal gemessene Länge einer Strecke, die diese zwei Punkte verbindet. Ein Distanzwert von Null bedeutet dabei, dass die Objekte einen Abstand von Null aufweisen, also identisch sind.
Die Formel für die Berechnung der euklidischen Distanz für \(n\) verschiedenen Variablen lautet:
\[d(A,B) = \sqrt{\sum_{i=1}^{n}(A_i - B_i)^2}\] Die Formel kann in einem zweidimensionalen Koordinatensystem mit den beiden Variablen \(X\) und \(Y\) (d.h. n = 2) wie folgt visualisiert werden:
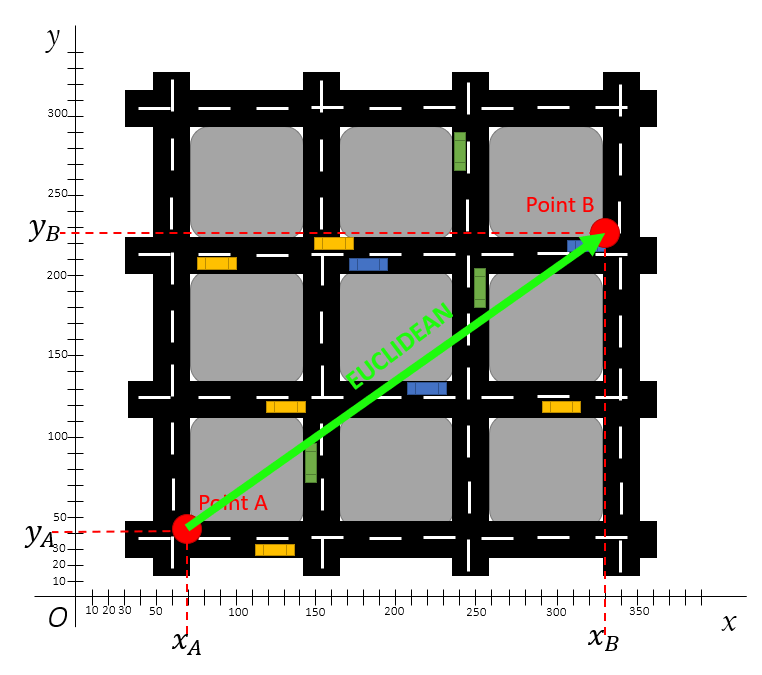
Wie aus dem Punktediagramm entnommen werden kann, gelten für die Punkte A und B:
- \(x_A\) = 70
- \(x_B\) = 330
- \(y_A\) = 40
- \(y_B\) = 228
Da wir in diesem Beispiel nur 2 Variablen vorliegen haben (n = 2), gilt hier ein bekannter Spezialfall der Berechnung des euklidischen Abstandes: der Satz des Pythagoras. Für die Berechnung der euklidischen Distanz werden daher lediglich die (X,Y)-Koordinaten benötigt um mit Hilfe der Formel von Pythagoras die Distanz zu berechnen:
\[d(A,B) = \sqrt{(x_A-x_B)^2 + (y_A-y_B)^2}\]
\[d(A,B) = \sqrt{(70-330)^2 + (40-228)^2}\]
\[d(A,B) = \sqrt{(-260)^2 + (-188)^2}\]
\[d(A,B) = \sqrt{(76600 + 35344) }\]
\[d(A,B) = \sqrt{(112225) }\]
\[d(A,B) = 335\]
Quadrierte euklidische Distanz
Anstelle der einfachen euklidischen Distanz kann auch die quadrierte euklidische Distanz als Distanzmaß genutzt werden. Dadurch werden größere Abweichungen stärker gewichtet. Die Formel der quadrierten euklidischen Distanz lautet:
\[d^2(A,B) = \sum_{i=1}^{n}(A_i - B_i)^2\]
Für unser Datenbeispiel gilt daher:
\[d^2(A,B) = (x_A-x_B)^2 + (y_A-y_B)^2\]
\[d^2(A,B) = (70-330)^2 + (40-228)^2\]
\[d^2(A,B) = 112225\]
\(L_1\)-Distanz
Die \(L_1\)-Distanz (auch Manhattan-Metrik, Manhattan-Distanz, Mannheimer Metrik, Taxi- oder Cityblock-Metrik) ist eine Metrik, in der die Distanz \(d\) zwischen zwei Punkten \(A\) und \(B\) als die Summe der absoluten Differenzen ihrer Einzelkoordinaten definiert wird. Dies ist insbesondere bei der Berechnung von geografischen Abständen relevant, bei welchen der Abstand zwischen zwei Punkten über vordefinierte Wege (bspw. Straßen in einer Stadt mit einer blockartigen Struktur wie in Manhattan oder Mannheim) zurückgelegt werden muss.

Wie aus der Abbildung ersichtlich wird, existieren mehrere Möglichkeiten, den Abstand zwischen den Punkten A und B zu berechnen. Wichtig ist jedoch, dass die “Straßen” nicht verlassen werden dürfen. D.h. es können bspw. zwei Blöcke nach oben (Norden) und dann drei Blöcke nach rechts (Osten) auf der Fahrbahn zurückgelegt werden, um von Punkt A aus Punkt B zu erreichen. Unabhängig von dem gewählten Pfad ist die Distanz aufgrund der blockartigen Struktur immer die gleiche.
Allgemein lautet die Formel für die Berechnung des L1-Abstands wie folgt:
\[d(A,B) = \sum_{i} |A_i - B_i|\]
In unserem Fall gilt:
\[d(A,B) = |x_A - x_B| + |y_A - y_B |\]
\[d(A,B) = |70 - 330| + |40 - 228 |\]
\[d(A,B) = |-260 | + |-188|\]
\[d(A,B) = 260 + 188\]
\[d(A,B) = 448 \]
Clustering-Algorithmus
Ist das Proximitätsmaß berechnet, so wird anhand eines Clustering-Algorithmus die eigentliche Gruppierung der Daten vorgenommen. In dieser Abbildung sind beispielhaft einige Clustering-Algorithmen aufgeführt:
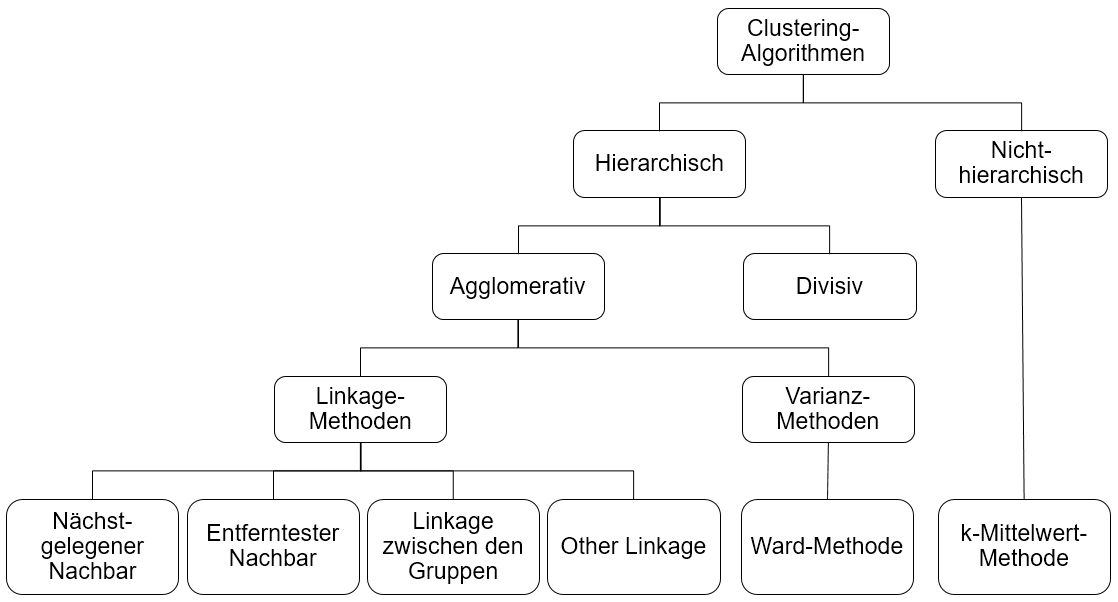
Bei den hier dargestellten Algorithmen wird zwischen hierarchischen und nicht-hierarchischen Algorithmen unterschieden. Im Rahmen dieses Tutorials werden ausschließlich hierarchische Algorithmen behandelt. Diese werden weiter in agglomerative und divisive Verfahren unterteilt.
Bei divisiven Verfahren wird zunächst ein Cluster gebildet, welches alle Datenpunkte enthält. Dieses wird dann schrittweise in kleinere Cluster zerteilt, bis jeder Fall ein eigenes Cluster bildet. Bei agglomerativen Verfahren werden die Datenpunkte zuerst einzeln betrachtet (d.h. jeder Fall ist ein eigenes Cluster) und dann schrittweise zu größeren Clustern zusammengefasst. Die agglomerativen Verfahren werden in Linkage-Methoden und Varianz-Methoden unterteilt.
Bei den Linkage-Methoden wird in jedem Schritt nach einer bestimmten Logik geprüft, welche Cluster den geringsten Abstand zueinander aufweisen. Diese Cluster werden dann zu einem neuen Cluster fusioniert. Je nach Linkage-Methode wird diese Distanz zwischen den Clustern unterschiedlich bestimmt (Universität Zürich, 2018):
- Nächstgelegener Nachbar (engl. “single linkage”): Das Minimum aller möglichen Distanzen zwischen den Datenpunkten in Cluster 1 und jenen in Cluster 2 wird betrachtet:

{kind=link}
- Entferntester Nachbar (engl. “complete linkage”): Das Maximum aller möglichen Distanzen zwischen den Datenpunkten in Cluster 1 und jenen in Cluster 2 wird betrachtet:

{kind=link}
- Linkage zwischen Gruppen (engl. “average linkage”): Der Mittelwert aller möglichen Distanzen zwischen den Datenpunkten in Cluster 1 und jenen in Cluster 2 wird betrachtet.

{kind=link}
- Other Linkage: Dies umfasst verschiedene Methoden. Beispielsweise wird die Distanz zwischen dem Median von Cluster 1 und dem Median von Cluster 2 betrachtet (Median-Clustering):

{kind=link}
Neben den Linkage-Methoden exisiteren noch weitere Methoden. Die Ward-Methode ist eine beliebte Varianz-basierte-Methode. Dabei werden die Cluster, die den kleinsten Zuwachs der totalen Varianz aufweisen, fusioniert. Die Methode ist daher eine Erweiterung der empirischen Varianz einer Variablen auf den multivariaten Fall.
Formel der empirischen Varianz:
\[s^2 = \frac{1}{n} \sum_{i=1}^{n}(x_i - \bar{x})^2\]
Formel der totalen Varianz (Streuung eines multivariaten Datensatzes mit \(p\) Variablen \(X_j\)):
\[T = \frac{1}{n}\sum_{j=1}^{p} \sum_{i=1}^{n}(x_{ij} - \bar{x_j})^2\]
In den Formeln wird ersichtlich, dass \((x_i-\bar{x})^2\) mit der bereits bekannten quadrierten euklidischen Distanz \(d^2(x_i,\bar{x})\) übereinstimmt. Es wird also für jedes Cluster die Summe der quadrierten Distanzen der Einzelfälle vom jeweiligen Cluster-Mittelwert berechnet. Diese Werte werden dann über alle Variablen \(p\) aufsummiert. Im nächsten Schritt werden jeweils jene zwei Cluster fusioniert, deren Zusammenfügen die geringste Erhöhung der Gesamtsumme der quadrierten Distanzen zur Folge hat.
In dieser Abbildung sind die Ergebnisse der verschiedenen Clustering-Algorithmen für unterschiedliche Datensätze exemplarisch dargestellt (Quelle: scikit-learn):

Bei den agglomerativen Verfahren führt das single linkage Verfahren in einigen Fällen zu einer sehr einseitigen Verteilung der Cluster. Die Ward Methode führt dagegen in den meisten Fällen zu einer relativ ausgeglichenen Aufteilung. Im folgenden Beispiel wird ebenfalls die Ward-Methode genutzt.
Implementierung in R
Für die Durchführung der hierarchischen Clusteranalyse mit der Ward-Methode nutzen wir die Daten des World Happiness Reports aus dem Jahr 2020. Der World Happiness Report ist ein jährlich vom Sustainable Development Solutions Network der Vereinten Nationen veröffentlichter Bericht. Der Bericht enthält Ranglisten zur Lebenszufriedenheit in verschiedenen Ländern der Welt und Datenanalysen aus verschiedenen Perspektiven (siehe Helliwell et al., 2020).
Import der Daten:
library(tidyverse)
df <- read_csv("https://raw.githubusercontent.com/kirenz/datasets/master/whr_20.csv")In dieser Analyse nutzen wir die landesspezifischen Informationen zu der Lebenserwartung in Jahren (healthy_life_expectancy) und das logarithmierte Bruttoinlandsprodukt pro Einwohner (logged_gdp_per_capita):
df %>%
ggplot(aes(logged_gdp_per_capita,
healthy_life_expectancy,
label = country_name )) +
geom_point() +
geom_text(check_overlap = TRUE,
vjust = 0, nudge_y = 0.5) +
theme_classic() +
ylab("Lebenserwartung") +
xlab("Bruttoinlandsprodukt pro Einwohner (logarithmiert)") 
Damit die Vorgehensweise des hierarchischen Clustering-Algorithmus besser nachvollzogen werden kann, ziehen wir zufällig 20 Länder aus dem Datensatz:
set.seed(1234)
df <- df %>%
sample_n(20)Darstellung der Länder in einem Punktediagramm:
df %>%
ggplot(aes(logged_gdp_per_capita,
healthy_life_expectancy,
label = country_name )) +
geom_point() +
geom_text(size = 3,
check_overlap = FALSE,
vjust = 0, nudge_y = 0.5) +
theme_classic() +
ylab("Lebenserwartung") +
xlab("Bruttoinlandsprodukt pro Einwohner (logarithmiert)") 
Datenvorbereitung
Variablenauswahl
Wir erzeugen einen neuen Datensatz df_cl, in welchem nur die Variablen enthalten sind, die für die Clusteranalyse genutzt werden sollen. Zusätzlich nutzen wir die Variable country_name, um in einem späteren Schritt die Daten sinnvoll beschriften zu können.
df_cl <- select(df, c("country_name",
"logged_gdp_per_capita",
"healthy_life_expectancy"))Fehlende Werte
Wir prüfen, ob in den Daten fehlende Werte vorliegen:
sum(is.na(df_cl))[1] 0In diesem Datensatz liegen keine fehlenden Werte vor. Falls dies in einem anderen Projekt jedoch der Fall sein sollte, könnten wir diese fehlenden Werte mit dem Befehl drop_na() entfernen:
df_cl <- drop_na(df_cl)Standardisierung
Damit die Werte der Variablen in einem einheitlichen Werteintervall vorliegen, nutzen wir für die Standardisierung der Daten die z-Transformation. Mit Hilfe dieser Standardisierung wird der Mittelwert auf 0 und die Standardabweichung der Variablen auf 1 gesetzt. Die Formel dafür lautet:
\[z = \frac{x - \bar{x}}{s}\]
- \(\bar{x}\): Mittelwert der Daten
- \(s\): Standardabweichung der Daten
Wir führen die Standardisierung mit Hilfe des Befehls scale() durch und speichern die neuen Variablen in dem Datensatz ab.
df_cl$healthy_life_expectancy_sc <- scale(df_cl$healthy_life_expectancy,
center = TRUE,
scale = TRUE)
df_cl$logged_gdp_per_capita_sc <- scale(df_cl$logged_gdp_per_capita,
center = TRUE,
scale = TRUE)Wie in der Abbildung nachvollzogen werden kann, ändert sich nicht die Position der Länder, sondern lediglich die Einheiten auf der X- und Y-Achse:
df_cl %>%
ggplot(aes(logged_gdp_per_capita_sc,
healthy_life_expectancy_sc,
label = country_name)) +
geom_point() +
geom_text(size = 3,
check_overlap = FALSE,
vjust = 0, nudge_y = 0.1) +
theme_classic() +
ylab("Lebenserwartung (z-Werte)") +
xlab("Bruttoinlandsprodukt pro Einwohner (z-Werte)") 
Proximitätsmaß
Wir nutzen als Proximitätsmaß die euklidische Distanz und speichern das Ergebnis der Funktion dist(), welche die Distanz zwischen allen Ländern berechnet, mit der Bezeichnung d ab. Da wir die Variable country_name nicht mit in die Berechnung einbeziehen möchten, entfernen wir diese in dem select()-Befehl.
d <-
df_cl %>%
select(-country_name) %>%
dist(method = "euclidean")Hierarchische Clusteranalyse
Im nächsten Schritt wird die hierarchische Clusteranalyse mit dem Befehl hclust() angewendet. Dafür übergeben wir der Funktion das Datenobjekt d, welches die euklidischen Distanzen zwischen den Ländern enthält (für weitere Hinweise zu der Funktion, siehe diesen Beitrag auf stackoverflow).
hc <- hclust(d, method = "ward.D2") Zu Beginn der agglomerativen Cluster-Bildung ist jedes Land in einem eigenen Cluster. Am Ende sind alle Länder in einem gemeinsamen Cluster. Die optimale Clusteranzahl wird dabei nicht von dem Algorithmus bestimmt, sondern muss auf Grundlage weiterer Überlegungen ermittelt werden. Bei der Bestimmung der optimalen Clusteranzahl ist die sogenannte “Cophenetic Distance” und das “Dendogramm” hilfreich.
Zu Beginn der agglomerativen Clusterbildung werden diejenigen Länder fusioniert, welche die geringste Distanz zueinander aufweisen. Diese “geringste Distanz” zwischen zwei Clustern, bei welcher die Zusammeführung stattfindet, kann mit der “Cophenetic Distance” bestimmt werden:
sort(unique(cophenetic(hc))) [1] 0.4446962 0.4991792 0.6219964 0.8162091 0.9668424 1.2776699
[7] 1.5519296 1.8267467 2.2893469 2.3881172 2.7432910 3.0358361
[13] 3.5850849 4.3343418 4.7705415 4.9156397 14.3947213 14.9659808
[19] 41.2573679Die geringste Distanz zwischen zwei Clustern beträgt zu Beginn (wenn jedes Land sein eigenes Cluster darstellt) 0.44. Dies war also der geringste Abstand zwischen zwei Ländern. Danach steigt der Abstand monoton steigend an, da immer unähnlichere Cluster (d.h. mit einem größeren Abstand zueinander) fusioniert werden. Bei der letzten Zusammenführung der Cluster in ein einziges gemeinsames Cluster nimmt die Distanz den Maximalwert von 41 an. Damit die Werte leichter interpretierbar sind, wird der Prozess üblicherweise in einem sogenannten Dendrogramm dargestellt.
Dendrogramm
Mit Hilfe des Dendrogramms kann das Ergebnis des Clustering-Algorithmus dargestellt werden. Das Dendrogramm liest sich dabei von unten nach oben und beschreibt in diese Richtung den Prozess des Clusterings. Die vertikale Achse beschreibt die Heterogenität der Cluster mit der bereits erwähnten “Cophenetic Distance” (die in der Abbildung als Height bezeichnet wird). Auf der unteren Seite des Dendrogramms sind alle Fälle einzeln aufgelistet. Zunächst entspricht also jedes Land einem Cluster, was sich daran zeigt, dass jeder Fall eine eigene horizontale Linie aufweist. Diese Cluster werden von unten nach oben sukzessive zu größeren Clustern zusammengefügt. Die vertikalen Linien zeigen an, dass zwei Cluster fusioniert werden.
Darstellung des Dendrogramms:
plot(hc) 
Nutzung der Ländernamen als Labels in dem Dendrogramm:
hc$labels <- df$country_name
plot(hc)
Die “optimale” Anzahl der Cluster sollte insbesondere anhand inhalticher Interpretationen in Hinblick einer größtmöglichen Plausibilität der gebildeten Cluster geschehen. Zusätzlich kann der größte (bzw. ein großer) Zuwachs der Heterogenität in dem Dendrogramm als Entscheidungskriterium genutzt werden. Bei unseren Daten entsteht der größte Heterogenitätszuwachs zwischen einer 2-Cluster und 1-Cluster-Lösung. Der Heterogenitätszuwachs zwischen einer 4-Cluster und 2-Cluster-Lösung ist ebenfalls relativ groß. Wir entscheiden uns hier für eine Clusteranzahl von 4, hätten jedoch auch die 2-Cluster-Lösung wählen können. Wie bereits erwähnt existiert bei diesem Verfahren oftmals keine eindeutige “optimale” Lösung, da jeweils auch die Interpretiertbarkeit der Cluster auf Grundlage inhaltlicher Überlegungen eine wichtige Rolle spielt.
Darstellung des Dendrogramms mit roten Grenzen bei einer Größe von 4 Clustern:
hc$labels <- df$country_name
plot(hc)
rect.hclust(hc, k = 4, border = "red")
Ermittlung der Gruppenzugehörigkeit (Cluster 1 bis Cluster 4) der jeweiligen Länder bei einer Clustergröße von k = 4. Dafür nutzen wir die Funktion cutree(), die einen “Schnitt” bei der entsprechenden Clustergröße vornimmt und die Daten in die entsprechenden Gruppen (Nummer des Clusters) einteilt.
gruppen <- cutree(hc, k = 4) Hinzufügung der Nummer des Clusters zu dem Datensatz:
df_cl$cluster <- gruppenDarstellung der Cluster in einem Punktediagramm:
df_cl %>%
ggplot(aes(logged_gdp_per_capita,
healthy_life_expectancy,
label = country_name,
color = factor(cluster))) +
geom_point() +
geom_text(size = 3,
check_overlap = FALSE,
vjust = 0, nudge_y = 0.5,
show.legend = FALSE) +
theme_classic() +
ylab("Lebenserwartung") +
xlab("Bruttoinlandsprodukt pro Einwohner (logarithmiert)") +
theme(legend.title=element_blank())
Zum Vergleich, hier noch die Aufteilung der Daten bei einer Wahl von 2 Clustern:
plot(hc)
rect.hclust(hc, k = 2, border = "red")
gruppen_2 <- cutree(hc, k = 2)
df_cl$cluster_2 <- gruppen_2Darstellung der 2-Cluster-Lösung in einem Punktediagramm:
df_cl %>%
ggplot(aes(logged_gdp_per_capita,
healthy_life_expectancy,
label = country_name,
color = factor(cluster_2))) +
geom_point() +
geom_text(size = 3,
check_overlap = FALSE,
vjust = 0, nudge_y = 0.5,
show.legend = FALSE) +
theme_classic() +
ylab("Lebenserwartung") +
xlab("Bruttoinlandsprodukt pro Einwohner (logarithmiert)") +
theme(legend.title=element_blank())